
TutorialBank: Learning NLP Made Easier
Published:
Introduction
Welcome! If you’ve made it here, you are probably interested in Natural Language Processing (NLP) or a related field (even if you’re not, keep reading!). NLP is rapidly growing, and, as a result, advancing in the field can seem daunting to the student or the researcher. To help the growing NLP community and advance research related to NLP for educational applications, we introduced a new corpus through our search engine called All About NLP (AAN) found at aan.how and in our paper “TutorialBank: Using a Manually-Collected Corpus for Prerequisite Chains, Survey Extraction and Resource Recommendation” (see github) by Alexander Fabbri, Irene Li, Prawat Trairatvorakul, Yijiao He, Weitai Ting, Robert Tung, Caitlin Westerfield and Dragomir Radev from the Language, Information, and Learning at Yale (LILY) lab.
What is TutorialBank?
TutorialBank is a manually collected dataset of about 6,500 resources on NLP as well as the related fields of Artificial Intelligence (AI), Machine Learning (ML) and Information Retrieval (IR). Over a few years we hand-picked high-quality resources related to these areas. These include surveys, tutorials, libraries, codebases, among others. We feel that students learn a lot from reading tutorials in addition to academic papers, so we focus on resources other than papers. For each resource, we populate our database with meta-data such as the type of resource (pedagogical function as stated in the paper) and categorize each one according to our own taxonomy of over 300 topics. The topics cover a wide range of areas, from fundamental data structures, algorithms and background material in mathematics and linguistics to state of the art advances in Deep Learning, Machine Translation and Reinforcement Learning, among others. Below are listed some of the topics:
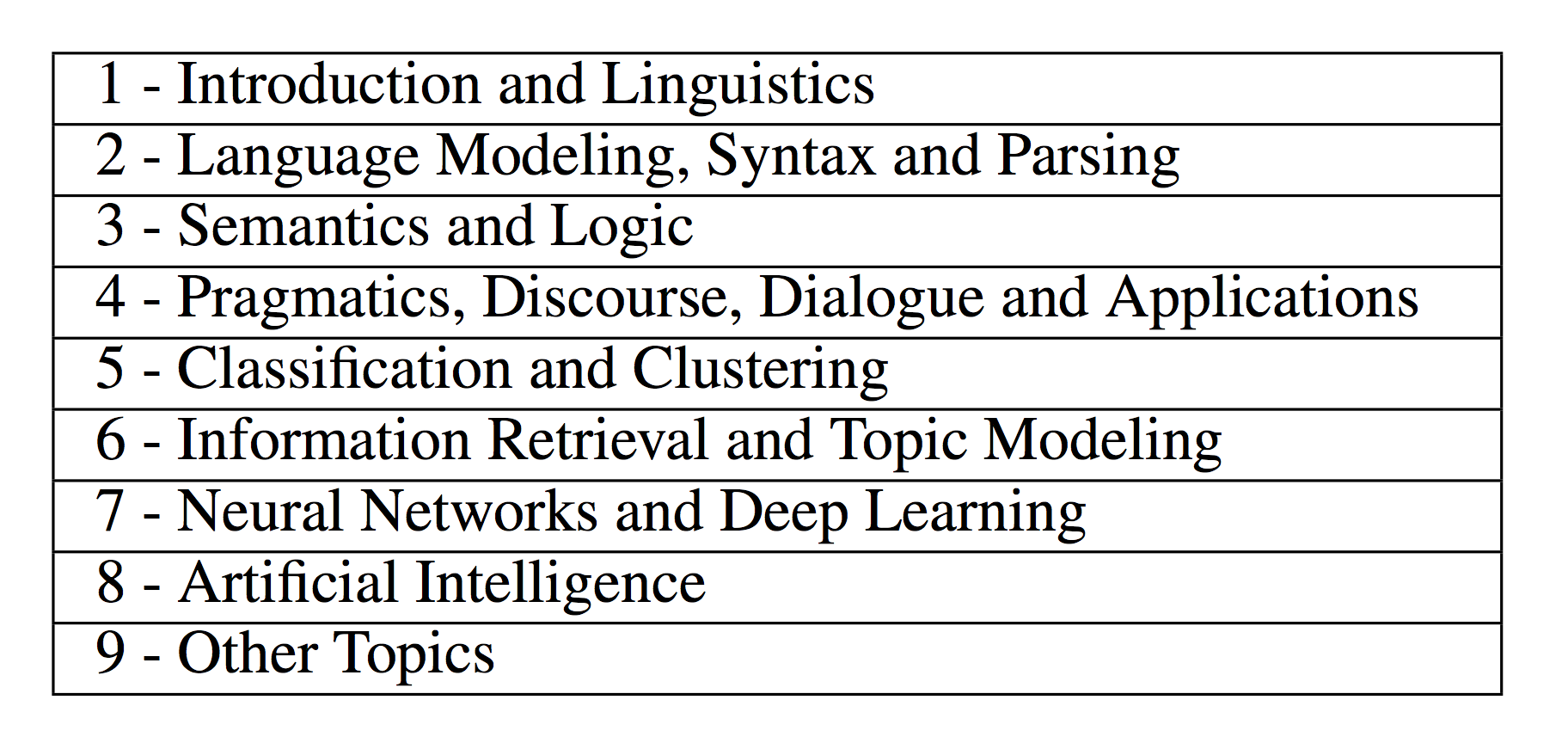 |
|---|
| The top level of the TutorialBank taxonomy |
How can I use TutorialBank?
Very easily! We created a search engine which we call “All About NLP” (AAN) and which you can use to quickly search our corpus (Access the corpus). The acronym AAN may be known to you from the ACL Anthology Network Corpus introduced here and here. We integrate our new search engine with the over 24,000 papeps from the ACL Anthology Reference Corpus and are constantly updating our search engine with new resources. You can explore our taxonomy of resources and pick the type of resource you are looking for by clicking “Browse Resources by Topic:”
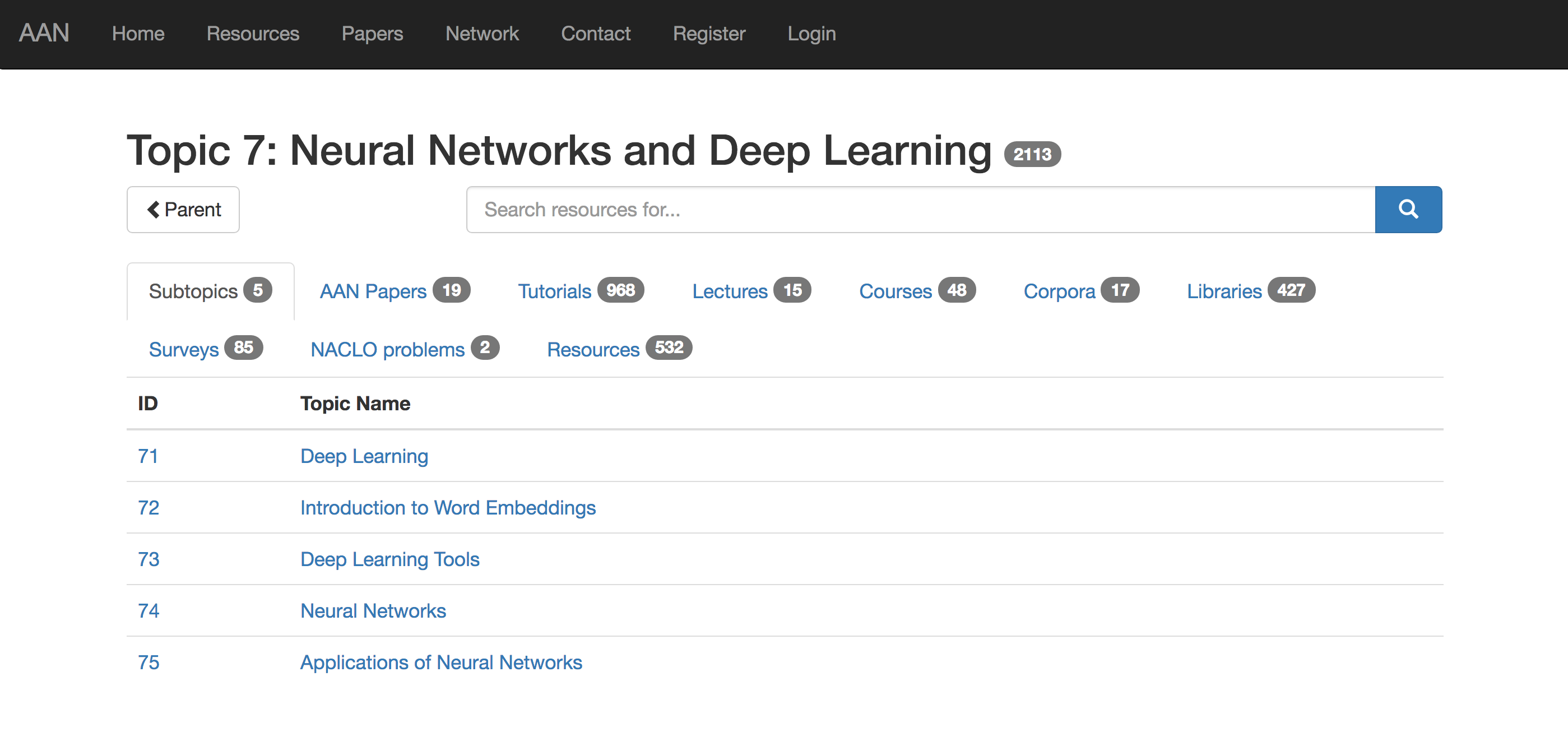 |
|---|
| In the mood to learn about Deep Learning? Look at all the resources we have for you! |
or you can just search for specific terms by clicking “Search Resources” as shown below:
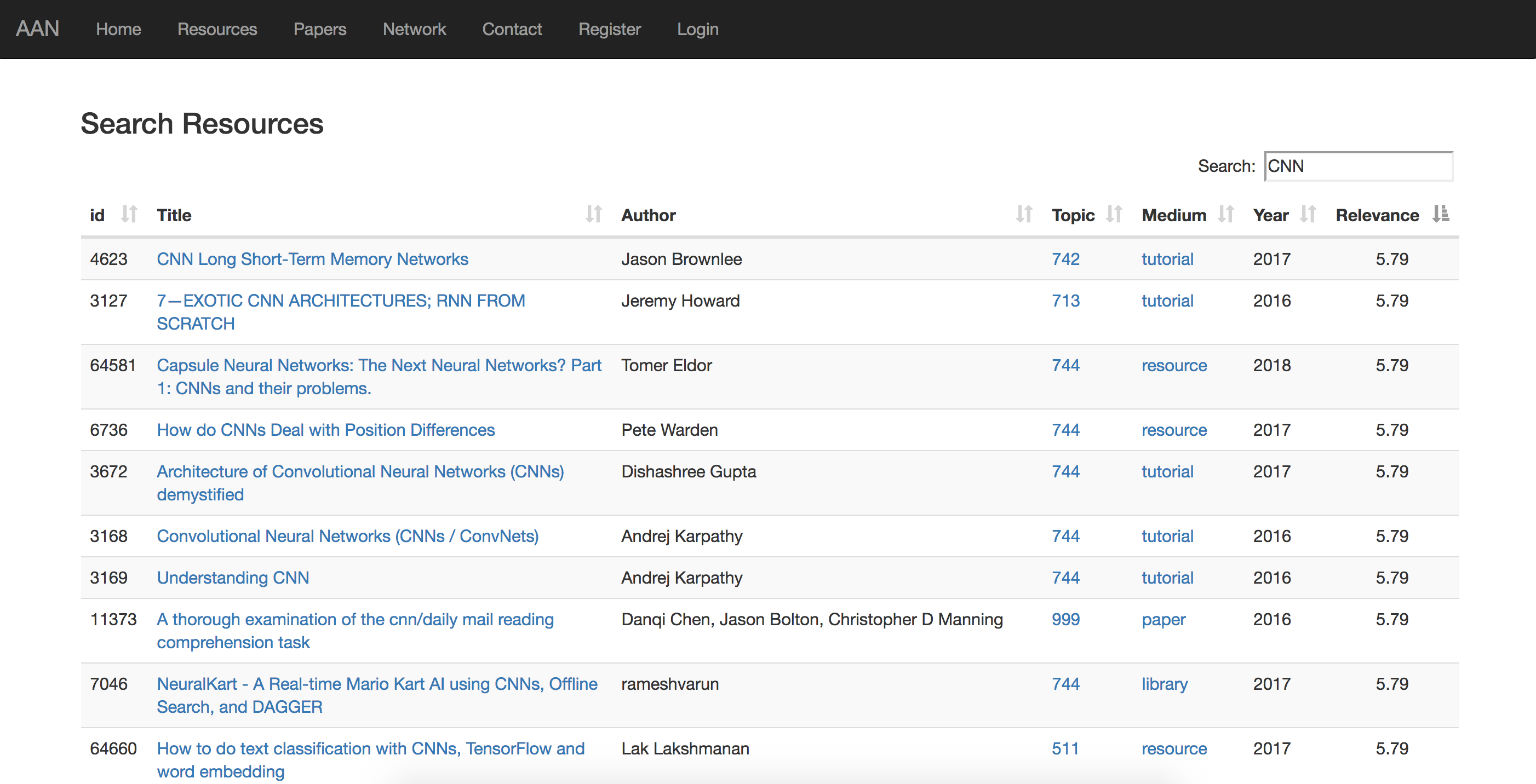 |
|---|
| I wish I had this resource before I did my homework on CNNs… |
Resource Recommendation
Another functionality of our site which we are excited about is recommending resources based on title and abstract pairs. Often times you may be given a task or have an early idea for a project and need to find resources to advance your ideas. Giving this starting point, we want to recommend resources for you to complete your project, like writing a bibliography made of tutorials! To access this feature, go to the Dashboard (requires login) and click on “Public Projects” to view examples or “My Projects” to create your own. We recommend topics from our taxonomy based on text matches in addition to a list of relevant resources from our corpus. We plan to improve upon the current baseline by exploring the relationship between title and abstract pairs. See below for sample outputs:
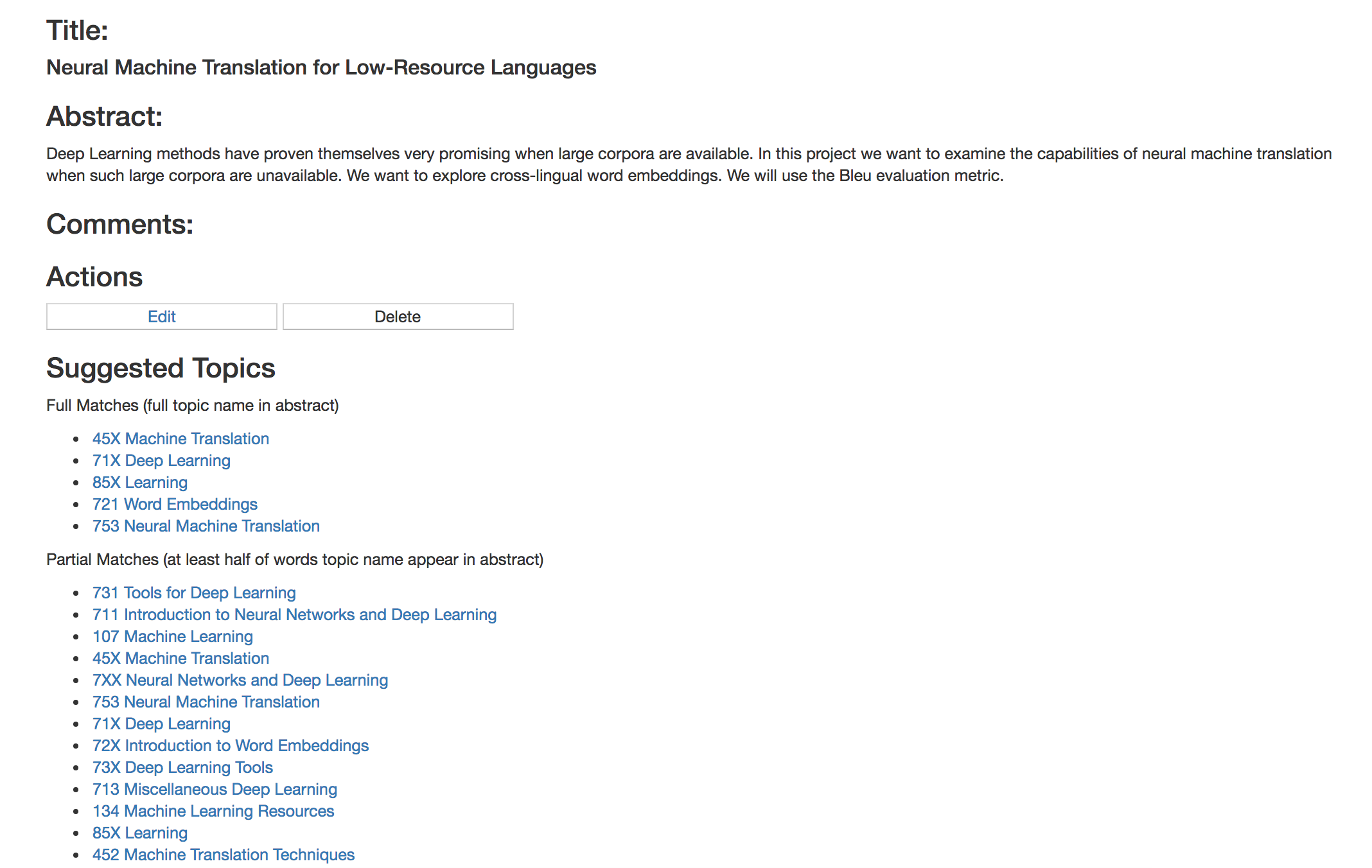 |
|---|
| Sample taxonomy topics for a project on low-resource machine translation |
 |
|---|
| The top 20 recommended resources for the above project |
Is there more?
Yes! While the collection of all these resources in a search engine is great in and of itself, we annotated our corpus to make it more useful for both the student and the researcher. Additionally, we created a simple command-line tool (available along with the corpus) to make our annotations more accessible, as described below.
Survey Topics, Reading Lists and Prerequisite Chains
We created a list of 200 topics for which we felt a survey of the topic would benefit students. As stated in the paper, these topics differ from the taxonomy topics, since we do not want our survey topics to be too broad or fine-grained. For each topic, annotators created reading lists of up to 5 resources on the topic. We then split up resources from these lits into content cards and abeled the cards as useful or not for learning the topic at hand. This is important since often resources are on a more general topic and only partly cover the topic you want to learn about.
What if you don’t know which topic to start with? To address this question, we annotated which topics are prerequisites of which other topics; which topics should you learn to better understand a given topic. A subsection of our graph is shown below:
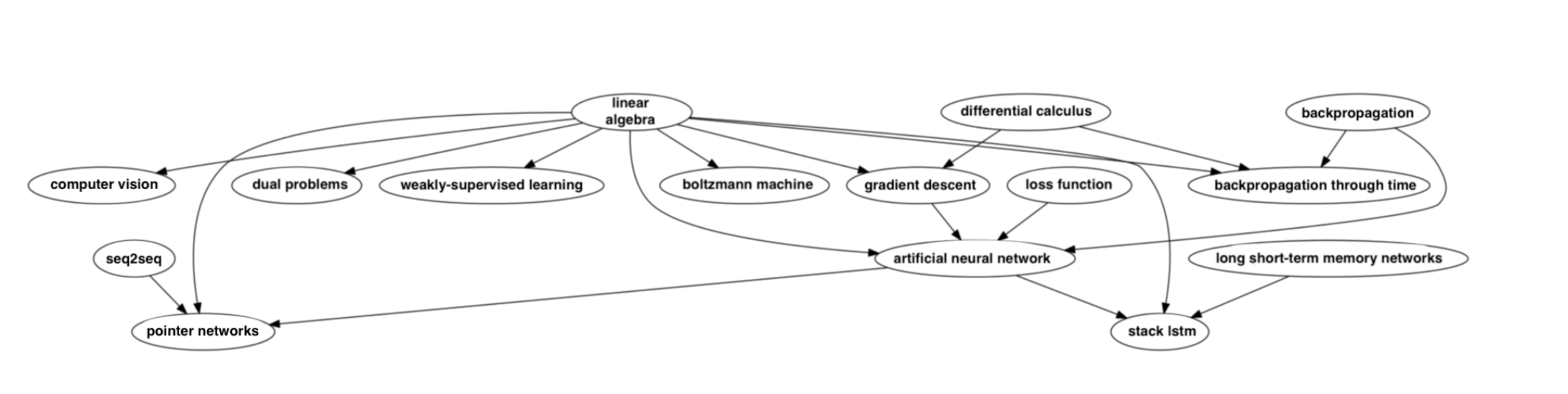 |
|---|
| Time to brush up! Where did I leave Gilbert Strang’s book? |
Accessing our annotations
That sounds like a mouthful to go through. Luckily for you, we created a command-line tool to make our annotations easily accessible:
 |
|---|
| Try out some of the options from our interface! |
 |
|---|
| Get a reading list for any of the annotated topics |
How can I use this for research?
We are releasing the links to the resources in our corpus (click here for a mysql dump of the resources). For copyright resons we are not including the full documents, but we are including scripts to download the resources which can be found here. Our annotations for resource type and topic categorization promote research in text classification and topic modeling while we hope our annotated reading lists and survey extraction annotations will promote information retrieval for scientific topics. Finally, our extensive prerequisite chain annotations can be used for learning concept dependencies in a supervised/semi-supervised manner.
How can I contribute?
AAN is built for you, the user, and so we greatly appreciate any feedback you may have. When you browse resources by topic, you can vote up or down for a particular resource. Such votes will help us determine what type of resources are popular and allow us to better add to the corpus in the future. Additionally, you can review a resource and share your thoughts and insights about that resource (example page). You can also report errors. For example, you may believe that the resource has been misclassified or the link may no longer point to the desired resource. For other issues and inqueries feel free to email me or send a message under “Contact” on our site. Finally, you may want to suggest a valuable resource which is not currently part of our corpus. You may do so from the Dashboard (requires login) by clicking on the Suggest Resource link. Our group will make the final decision on the inclusion of a suggested resource. We require that the resource be of general interest to the broader community.
What can I expect in the future?
In the future we are planning to expand our taxonomy and corpus for broader coverage. We are also going to add new features to our site and improve the existing algorithms for search and recommendation. Additionally, we are planning to refine our annotations and explore more deeply the research areas of prerequisite chains, resource recommendation and survey extraction.
Reference
If you plan to use some of this in your work, please cite our paper:
@InProceedings{fabbri2018tutorialbank,
author = {Fabbri, Alexander R and Li, Irene and Trairatvorakul, Prawat and He, Yijiao and Ting, Wei Tai and Tung, Robert and Westerfield, Caitlin and Radev, Dragomir R},
title = {TutorialBank: A Manually-Collected Corpus for Prerequisite Chains, Survey Extraction and Resource Recommendation},
year = {2018},
booktitle = {Proceedings of ACL},
publisher = {Association for Computational Linguistics}
}